
The roads I take...
KaiRo's weBlog
| Zeige Beiträge veröffentlicht im August 2011 und mit "CrashKill" gekennzeichnet an. Zurück zu allen aktuellen Beiträgen | |||||||||||||||||||||||||||||||||||||||||||
27. August 2011
Why Rapid Releases Can Improve Stability
I have mentioned a few times, mostly in newsgroup discussions, that I strongly believe that the rapid release model Firefox is following now has a good chance to improve stability.
Some people without a deeper knowledge of how our new process works have at times implied that releasing way more often must make the product more unstable and worse quality than the one or two year cycles we had before. Given my multi-year experience in release management of a Mozilla product (SeaMonkey) and along with that insight into Firefox release management of the last few versions up to and including Firefox 4, my comparison of those experiences with the new model point into the exact opposite direction: Stability and quality should actually improve the more we get used to this "train" model and also the more we near the prospected user volume on the different "channels".
"Traditional" Process
Let's first look at how things worked with the old process that we used so far, including for Firefox 4: New work landed in the code for more than a year with first having only nightly testers run it every day, later alpha/beta testers running snapshots created along the way that included fixes found in some internal QA in addition to the nightly testing, but that was it for the alphas and betas - and at the point where those got shipped, we already had land the next set of feature changes on top of the code shipped there. From the view of crash analysis, this meant that we had a smaller audience of nightly testers sending crash reports we could analyze and from that see the larger and more obvious regressions from daily changes. And then there was a larger audience of beta testers that sent more data, which allowed a look at what happened with somewhat more real-world usage, but as soon as we got some good data in on those betas, the code on nightly on the way to the next beta might already have changed significantly again. With that, the most grave issues could be addressed, but sometimes it was hard to see how relevant the data from even the current beta still was. This game went on until the final betas, with increasing urgency of getting things in that should still make the release at the last second, and of course us as well as testers seeing new regressions that needed to be fixed. The criteria for accepting things into the code was being tightened up a lot towards final release, but some new feature work or invasive changes could even still be rushed into the code almost to the last minute. And the pressure was high to "get this in now or wait at least another year until users get it", so even with release drivers tightening possible changes up, some of those could still be argued for. When we shipped the final release to the really larger user audience with more than a year of piled up feature work and fixes, we very soon, usually even directly on release day or the next day, already have a list of quite visible stability problems we needed to get fixed a couple of weeks out in a stability update.
I hope you can see from this description that while we managed to control stability reasonably, the process was far from ideal for providing a product with which we could be happy in terms of stability. So when planning went into improving the processes and becoming more agile and fit for delivering features more quickly than before, a lot of thinking also went into how to make the new process give us a better story of stabilization - and I think the solution holds up pretty well.
"Rapid" Process
So, what we're doing now is getting in feature work and invasive changes into the base code and to Nightly testers almost as before, with only the difference that every such change must have an easy off-switch or be easy enough to reverse the change ("back it out") otherwise. We also still analyze crash data for this and spot major regressions there.
But with going to a next level, there comes the first major change: Every six weeks we're taking a snapshot of this Nightly code and put it on what we now call "Aurora", test it internally, disable things that are absolutely broken (as we have the off-switch/backout possibility) as found by internal QA and send it out to a somewhat larger testing audience. In the next six weeks, we are collecting data from that, reacting to user feedback and crash analysis and bringing in rather small fixes to those problems only or disable further broken features when a fix would be too invasive. We deliver the result daily to that Aurora audience in updates, getting more testing and crash data to analyze, based on the very same snapshot of code, without any more new feature or invasive work to go into it - that continues only on Nightly, no place for that in Aurora.
After those six weeks, this already fixed and stabilized snapshot is going to yet another level, which we call "Beta", and which has even more testers it's being delivered to (while Aurora picks up a new snapshot from Nightly). When the snapshot comes into the Beta phase, we have already put in six weeks of exclusively stabilization and fixing, so it is good enough for what we in earlier times probably would have called a "release candidate". It is as ready as we know at this stage as it can be - but exposing it to an even wider audience, now going into the millions, and which uses it for more normal day-to-day production work, usually turns up another class of potential problems. To deal with those, we could go and disable even more code if needed, and can apply some more small fixes, including of course crash fixes, and we deliver those to Beta testers with roughly weekly updates. Due to this being the first time this code snapshot is being exposed to a public of millions, it's usually the first time we get enough data to see some crash patterns more clearly and can get those fixed. Once again, no new feature or invasive work going into those six weeks of Beta, only disabling of problematic changes, fixing problems found in feedback and of course stability/crashes.
Having spent another six weeks in Beta, twelve weeks or three months of only fixing and stabilizing after taking the snapshot from development, and being OKed by a go/no-go meeting of release drivers, we ship this code to hundreds of millions of users as our next Firefox release (while the other snapshot moves from Aurora to Beta and yet another one is taken from Nightly into Aurora). Of course, we keep analyzing crash reports even from the release users and are able to react to large issues we haven't found before to do a fast fixup release (which we shouldn't need after looking at all the Aurora and Beta data from essentially the same code) and to smaller issues in the next round of Beta etc. before they go to being the next release.
In all this, we always have only six weeks of new development work isolated in every such snapshot (or "version") and not more than a year like previously, so pinpointing a cause gets easier. Then, we less of a rush to get a feature into a specific version as there's another one coming just six weeks earlier, so things will only go into the code in a better thought-out state. Even more, we have switches of some way we can throw to disable problematic code and give developers six more weeks to get it into shape if needed. And over all that, we have roughly three months (twelve weeks) of pure fixing and stabilization period on every snapshot/version to get problems worked out, with different sizes of testing audiences.
Of course, there are still some kinks to be worked out and the transition is not easy for everyone. Next to other concerns we've heard of some people and which belong in different forums than this particular blog entry, we have not scaled up the audiences esp. on Aurora but also on Beta up to what we want yet and therefore are not seeing as much data on them yet as we'd like to (the top crash/hang issue on Beta is typically seen by less than one in every 1000 daily users). So, there are still ways we can and need to improve things here to make it work for stability even better.
Still, having smaller sets of changes per release, no rushed landings of features and built-in calm stabilization periods of that length are all working together to improve stability, in my eyes - as long as people send in their crash reports and we continue to analyze them, of course.
Some people without a deeper knowledge of how our new process works have at times implied that releasing way more often must make the product more unstable and worse quality than the one or two year cycles we had before. Given my multi-year experience in release management of a Mozilla product (SeaMonkey) and along with that insight into Firefox release management of the last few versions up to and including Firefox 4, my comparison of those experiences with the new model point into the exact opposite direction: Stability and quality should actually improve the more we get used to this "train" model and also the more we near the prospected user volume on the different "channels".
"Traditional" Process
Let's first look at how things worked with the old process that we used so far, including for Firefox 4: New work landed in the code for more than a year with first having only nightly testers run it every day, later alpha/beta testers running snapshots created along the way that included fixes found in some internal QA in addition to the nightly testing, but that was it for the alphas and betas - and at the point where those got shipped, we already had land the next set of feature changes on top of the code shipped there. From the view of crash analysis, this meant that we had a smaller audience of nightly testers sending crash reports we could analyze and from that see the larger and more obvious regressions from daily changes. And then there was a larger audience of beta testers that sent more data, which allowed a look at what happened with somewhat more real-world usage, but as soon as we got some good data in on those betas, the code on nightly on the way to the next beta might already have changed significantly again. With that, the most grave issues could be addressed, but sometimes it was hard to see how relevant the data from even the current beta still was. This game went on until the final betas, with increasing urgency of getting things in that should still make the release at the last second, and of course us as well as testers seeing new regressions that needed to be fixed. The criteria for accepting things into the code was being tightened up a lot towards final release, but some new feature work or invasive changes could even still be rushed into the code almost to the last minute. And the pressure was high to "get this in now or wait at least another year until users get it", so even with release drivers tightening possible changes up, some of those could still be argued for. When we shipped the final release to the really larger user audience with more than a year of piled up feature work and fixes, we very soon, usually even directly on release day or the next day, already have a list of quite visible stability problems we needed to get fixed a couple of weeks out in a stability update.
I hope you can see from this description that while we managed to control stability reasonably, the process was far from ideal for providing a product with which we could be happy in terms of stability. So when planning went into improving the processes and becoming more agile and fit for delivering features more quickly than before, a lot of thinking also went into how to make the new process give us a better story of stabilization - and I think the solution holds up pretty well.
"Rapid" Process
So, what we're doing now is getting in feature work and invasive changes into the base code and to Nightly testers almost as before, with only the difference that every such change must have an easy off-switch or be easy enough to reverse the change ("back it out") otherwise. We also still analyze crash data for this and spot major regressions there.
But with going to a next level, there comes the first major change: Every six weeks we're taking a snapshot of this Nightly code and put it on what we now call "Aurora", test it internally, disable things that are absolutely broken (as we have the off-switch/backout possibility) as found by internal QA and send it out to a somewhat larger testing audience. In the next six weeks, we are collecting data from that, reacting to user feedback and crash analysis and bringing in rather small fixes to those problems only or disable further broken features when a fix would be too invasive. We deliver the result daily to that Aurora audience in updates, getting more testing and crash data to analyze, based on the very same snapshot of code, without any more new feature or invasive work to go into it - that continues only on Nightly, no place for that in Aurora.
After those six weeks, this already fixed and stabilized snapshot is going to yet another level, which we call "Beta", and which has even more testers it's being delivered to (while Aurora picks up a new snapshot from Nightly). When the snapshot comes into the Beta phase, we have already put in six weeks of exclusively stabilization and fixing, so it is good enough for what we in earlier times probably would have called a "release candidate". It is as ready as we know at this stage as it can be - but exposing it to an even wider audience, now going into the millions, and which uses it for more normal day-to-day production work, usually turns up another class of potential problems. To deal with those, we could go and disable even more code if needed, and can apply some more small fixes, including of course crash fixes, and we deliver those to Beta testers with roughly weekly updates. Due to this being the first time this code snapshot is being exposed to a public of millions, it's usually the first time we get enough data to see some crash patterns more clearly and can get those fixed. Once again, no new feature or invasive work going into those six weeks of Beta, only disabling of problematic changes, fixing problems found in feedback and of course stability/crashes.
Having spent another six weeks in Beta, twelve weeks or three months of only fixing and stabilizing after taking the snapshot from development, and being OKed by a go/no-go meeting of release drivers, we ship this code to hundreds of millions of users as our next Firefox release (while the other snapshot moves from Aurora to Beta and yet another one is taken from Nightly into Aurora). Of course, we keep analyzing crash reports even from the release users and are able to react to large issues we haven't found before to do a fast fixup release (which we shouldn't need after looking at all the Aurora and Beta data from essentially the same code) and to smaller issues in the next round of Beta etc. before they go to being the next release.
In all this, we always have only six weeks of new development work isolated in every such snapshot (or "version") and not more than a year like previously, so pinpointing a cause gets easier. Then, we less of a rush to get a feature into a specific version as there's another one coming just six weeks earlier, so things will only go into the code in a better thought-out state. Even more, we have switches of some way we can throw to disable problematic code and give developers six more weeks to get it into shape if needed. And over all that, we have roughly three months (twelve weeks) of pure fixing and stabilization period on every snapshot/version to get problems worked out, with different sizes of testing audiences.
Of course, there are still some kinks to be worked out and the transition is not easy for everyone. Next to other concerns we've heard of some people and which belong in different forums than this particular blog entry, we have not scaled up the audiences esp. on Aurora but also on Beta up to what we want yet and therefore are not seeing as much data on them yet as we'd like to (the top crash/hang issue on Beta is typically seen by less than one in every 1000 daily users). So, there are still ways we can and need to improve things here to make it work for stability even better.
Still, having smaller sets of changes per release, no rushed landings of features and built-in calm stabilization periods of that length are all working together to improve stability, in my eyes - as long as people send in their crash reports and we continue to analyze them, of course.
Von KaiRo, um 04:03 | Tags: CrashKill, Firefox, Mozilla, release | 2 Kommentare | TrackBack: 1
16. August 2011
Crash-stata Now Splits Data For Betas And Release
As already mentioned in my recent post about crash-stats, the Socorro team has been busy with more changes to how their server software works, as requested mostly by our team of crash analyzers.
After working late hours last week, working on the weekend for a first deployment on Sunday, and doing a bugfixing all-nighter until this morning, this great group of people made sure that we have better-fitting crash analysis infrastructure in place for today's Firefox release than for the last one six weeks ago.
So, what has changed? Doesn't the crash-stats front page look the same as before? Not entirely. The devil is in the details. The old one was almost, but not quite unlike the tea we wanted to drink. The new one actually is brewed out of leaves and hot water, to stay with the analogy borrowed from Douglas Adams. In the updated version we're running now, you'll see that on the front page we replaced "6.0" with "6.0(beta)" at this moment and in the next days we won't have completely unusable crash rates for the release, like we had for 5.0 six weeks ago.
The reason is that betas and releases are now processed very differently. We now get graphs and reports for every single beta build we push out, and for the final release build separately on the beta channel and on "the release channel" - even though all of those report in with exactly the same version number. When you see or select graphs for "6.0b1" through "6.0b5", Socorro actually internally looks for a "6.0" version number, the "beta" release channel and the right build ID that corresponds to the fifth build we created on the beta channel for 6.0.
When we generate the final release builds, we also push them to the beta channel, which is reported as "6.0(beta)" there, while "6.0" now only looks at other channels (mostly "release" but also things like the "default" channel used by e.g. Linux distro builds). As we process only 10% of all crashes in the latter category but 100% for the former, splitting those apart makes both have correct crash rates, being able to account for the difference with a factor (not being able to do that and mixing values for both caused unusable crash rate numbers in the last cycle).
In addition, the team also fixed a discrepancy between crash counts that have been previously done per Pacific Time day and ADUs which are done per UTC day - now both (for betas and releases) are counted per UTC day, making the rates more meaningful.
With all that, we now will be able to compare different betas against each other in a meaningful way, as well as beta and release, look for differences and spot regressions more easily. Still, note that this is for betas and releases only, while we have plans for improving Nightly and Aurora reporting as well, those for now stay with the "old" reports. Also, this is only the first stage, and small glitches are possible, though some more visible regressions have been fixed earlier today as mentioned.
Getting this to work was not "just adding a line of SQL" as someone suggested to me some time ago, but it required getting the necessary data in the correct tables, creating new data aggregation tables and mechanisms, fetching the needed data from the proper places, making the UI use the new aggregations and making other parts of the system play together with those changed reports properly. Many thanks to the Socorro team for getting all this done in time for today's Firefox release!
I hope the team gets some good sleep and rest after this now while we are starting to actually use their newest work, so they're fit for the future. In the end, we have more requests for improvements come their way as we're trying to get all the data we need for making Firefox even more stable - it's surely not a boring place to work at for either one of us...
After working late hours last week, working on the weekend for a first deployment on Sunday, and doing a bugfixing all-nighter until this morning, this great group of people made sure that we have better-fitting crash analysis infrastructure in place for today's Firefox release than for the last one six weeks ago.
So, what has changed? Doesn't the crash-stats front page look the same as before? Not entirely. The devil is in the details. The old one was almost, but not quite unlike the tea we wanted to drink. The new one actually is brewed out of leaves and hot water, to stay with the analogy borrowed from Douglas Adams. In the updated version we're running now, you'll see that on the front page we replaced "6.0" with "6.0(beta)" at this moment and in the next days we won't have completely unusable crash rates for the release, like we had for 5.0 six weeks ago.
The reason is that betas and releases are now processed very differently. We now get graphs and reports for every single beta build we push out, and for the final release build separately on the beta channel and on "the release channel" - even though all of those report in with exactly the same version number. When you see or select graphs for "6.0b1" through "6.0b5", Socorro actually internally looks for a "6.0" version number, the "beta" release channel and the right build ID that corresponds to the fifth build we created on the beta channel for 6.0.
When we generate the final release builds, we also push them to the beta channel, which is reported as "6.0(beta)" there, while "6.0" now only looks at other channels (mostly "release" but also things like the "default" channel used by e.g. Linux distro builds). As we process only 10% of all crashes in the latter category but 100% for the former, splitting those apart makes both have correct crash rates, being able to account for the difference with a factor (not being able to do that and mixing values for both caused unusable crash rate numbers in the last cycle).
In addition, the team also fixed a discrepancy between crash counts that have been previously done per Pacific Time day and ADUs which are done per UTC day - now both (for betas and releases) are counted per UTC day, making the rates more meaningful.
With all that, we now will be able to compare different betas against each other in a meaningful way, as well as beta and release, look for differences and spot regressions more easily. Still, note that this is for betas and releases only, while we have plans for improving Nightly and Aurora reporting as well, those for now stay with the "old" reports. Also, this is only the first stage, and small glitches are possible, though some more visible regressions have been fixed earlier today as mentioned.
Getting this to work was not "just adding a line of SQL" as someone suggested to me some time ago, but it required getting the necessary data in the correct tables, creating new data aggregation tables and mechanisms, fetching the needed data from the proper places, making the UI use the new aggregations and making other parts of the system play together with those changed reports properly. Many thanks to the Socorro team for getting all this done in time for today's Firefox release!
I hope the team gets some good sleep and rest after this now while we are starting to actually use their newest work, so they're fit for the future. In the end, we have more requests for improvements come their way as we're trying to get all the data we need for making Firefox even more stable - it's surely not a boring place to work at for either one of us...
Von KaiRo, um 22:42 | Tags: CrashKill, Mozilla, Socorro | keine Kommentare | TrackBack: 1
3. August 2011
Crash-stats Update, Planned Changes, And Crash Rates
Those people who monitor the front page of the Mozilla crash stats website probably have noted a significant change today. If you are usually looking at Fennec stats there and therefore have saved a cookie that points you to Fennec by default, the graph there looks something like this today:
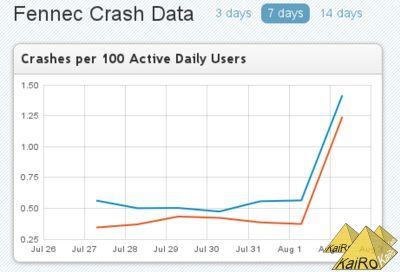
Now, did released "stable" and beta versions of Firefox Mobile suddenly become almost 3 times as crashy within a day?
Thankfully not. The data on the graphs actually was undercounting crashes until the newest set.
Last night, the Socorro team released their newest release, 2.1, to our production servers. That didn't just mean that colors on more detailed graphs are fixed and that source code should be linked correctly even for aurora and beta trees, it most of all means that crash counts now include all actual reports, for Fennec that is very significant, as crashes in content (website) processes have not been counted so far.
So, starting with the August 2 numbers (no old numbers are being backfilled), the system actually counts and displays crashes in websites in Fennec numbers and rates - and as we encounter almost double the amount of crashes in content processes than in browser processes on mobile, the total numbers seem to roughly triple.
This also means that the reported rates for Fennec are in the same general area as the Firefox desktop numbers - at least they match what was listed for them until yesterday. People who have been watching those numbers might recognize a change in this graph as well:
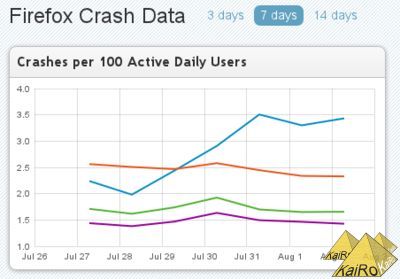
And I mean neither that the blue line for Nightly is very high due to some recent regressions that our developers are working on, nor that Aurora (orange) is visibly going down after we fixed a prominent Flash hang (but more work is needed on crashes there), nor that Beta (green, the Flash hang fix not yet being visible) and Release show slightly higher rates on the weekend (Jul 30/31). Those are all normal mechanics.
I mean that numbers there for all days and versions looked somewhat lower yesterday than they do today. Beta and Release were almost identical before, slightly below that 1.5 line, and now they're distinct and mostly over that line.
As I hinted above, this is due to including *all* reports now, and due to a difference with mobile. And it's not content processes, which we don't have on desktop - but websites are still crashing mostly the same. It's data we have counted before (that's why it affects previous days as well) but not displayed in graphs: plugin crashes.
Fennec right now doesn't support plugins, so the 0.4-0.5 "crashes per 100 ADU" we see on Firefox desktop releases, mostly from Flash, but also other plugins, probably some even crashes in our plugin process that are not the plugins themselves, are missing out there, and that explains the remaining difference in rates between Fennec and Firefox. It also explains why graphs changed across the board today.
But the team is already working on more changes to come very soon:
Right now all builds with the same version number are lumped together in the same graphs and topcrash reports - but in the future, we need to tell apart different Beta builds so we can see if one beta is better than the previous one. We also need to be able to tell apart a release build on the beta and release channels, as the people on those channels have different usage habits, and even more importantly, we throttle crash reports on the release channel (we only process and therefore count 10% of the reports, actually, to not overwhelm server storage) but not on beta, which made crash rate calculations be quite useless around the last release. Because of that, the team is working hard to get this work done before we go for the next release on August 16, and then we should have useful numbers this time around.
This will also mean that we will have distinct numbers for every beta in the next cycle, which will be very helpful but probably will have its own fun repercussions - I should blog about that when this comes around.
I'd like to close out this post with some words of general caution when looking at crash rates or numbers: Never take them as a general stability measure without monitoring more closely what's behind them and why they look like they do!
Those rates lump together all kinds of issues:
If you look at this list, it becomes pretty clear that using those numbers as a firm measure of how stable a release or version is probably is not a really fair value. Still, the numbers are quite helpful in discovering if there is some kind of regression or new issue, if there is a good or bad trend, if some fix for a large issue has an overall effect - but following that discovery, we need to look closely at what the discovered issue really is and how we need to deal with it - that can be getting our developers to look into it, contacting third parties to work on a fix, blocking some add-on or library, advising release drivers of problems to track, etc. - and that's what's actually the job the CrashKill team, including myself, ends up doing most of the day.
Now, did released "stable" and beta versions of Firefox Mobile suddenly become almost 3 times as crashy within a day?
Thankfully not. The data on the graphs actually was undercounting crashes until the newest set.
Last night, the Socorro team released their newest release, 2.1, to our production servers. That didn't just mean that colors on more detailed graphs are fixed and that source code should be linked correctly even for aurora and beta trees, it most of all means that crash counts now include all actual reports, for Fennec that is very significant, as crashes in content (website) processes have not been counted so far.
So, starting with the August 2 numbers (no old numbers are being backfilled), the system actually counts and displays crashes in websites in Fennec numbers and rates - and as we encounter almost double the amount of crashes in content processes than in browser processes on mobile, the total numbers seem to roughly triple.
This also means that the reported rates for Fennec are in the same general area as the Firefox desktop numbers - at least they match what was listed for them until yesterday. People who have been watching those numbers might recognize a change in this graph as well:
And I mean neither that the blue line for Nightly is very high due to some recent regressions that our developers are working on, nor that Aurora (orange) is visibly going down after we fixed a prominent Flash hang (but more work is needed on crashes there), nor that Beta (green, the Flash hang fix not yet being visible) and Release show slightly higher rates on the weekend (Jul 30/31). Those are all normal mechanics.
I mean that numbers there for all days and versions looked somewhat lower yesterday than they do today. Beta and Release were almost identical before, slightly below that 1.5 line, and now they're distinct and mostly over that line.
As I hinted above, this is due to including *all* reports now, and due to a difference with mobile. And it's not content processes, which we don't have on desktop - but websites are still crashing mostly the same. It's data we have counted before (that's why it affects previous days as well) but not displayed in graphs: plugin crashes.
Fennec right now doesn't support plugins, so the 0.4-0.5 "crashes per 100 ADU" we see on Firefox desktop releases, mostly from Flash, but also other plugins, probably some even crashes in our plugin process that are not the plugins themselves, are missing out there, and that explains the remaining difference in rates between Fennec and Firefox. It also explains why graphs changed across the board today.
But the team is already working on more changes to come very soon:
Right now all builds with the same version number are lumped together in the same graphs and topcrash reports - but in the future, we need to tell apart different Beta builds so we can see if one beta is better than the previous one. We also need to be able to tell apart a release build on the beta and release channels, as the people on those channels have different usage habits, and even more importantly, we throttle crash reports on the release channel (we only process and therefore count 10% of the reports, actually, to not overwhelm server storage) but not on beta, which made crash rate calculations be quite useless around the last release. Because of that, the team is working hard to get this work done before we go for the next release on August 16, and then we should have useful numbers this time around.
This will also mean that we will have distinct numbers for every beta in the next cycle, which will be very helpful but probably will have its own fun repercussions - I should blog about that when this comes around.
I'd like to close out this post with some words of general caution when looking at crash rates or numbers: Never take them as a general stability measure without monitoring more closely what's behind them and why they look like they do!
Those rates lump together all kinds of issues:
- Regressions in our code that cause crashes,
- a long tail of residual crash issues in our code,
- binary libraries of valid third-party software or adware/malware hooking into our code and causing crashes due to incompatibilities, often because they're crafted for peculiarities of some other Firefox version,
- security tools like e.g. Norton Site Advisor or AVG not knowing that particular Firefox version and causing crashes by blocking it,
- add-ons with crashy code or incompatibilities,
- operating system or driver libraries that we call ending up crashing or showing incompatibilities with our code,
- out of memory issues,
- plugins (often Flash) crashing or not reacting in time (hanging), sometimes even crashing the browser process,
- website changes or new websites uncovering lingering crash issues (often from the long tail of residual crashes),
- and probably some more.
If you look at this list, it becomes pretty clear that using those numbers as a firm measure of how stable a release or version is probably is not a really fair value. Still, the numbers are quite helpful in discovering if there is some kind of regression or new issue, if there is a good or bad trend, if some fix for a large issue has an overall effect - but following that discovery, we need to look closely at what the discovered issue really is and how we need to deal with it - that can be getting our developers to look into it, contacting third parties to work on a fix, blocking some add-on or library, advising release drivers of problems to track, etc. - and that's what's actually the job the CrashKill team, including myself, ends up doing most of the day.
Von KaiRo, um 18:32 | Tags: CrashKill, Mozilla, Socorro | keine Kommentare | TrackBack: 1
