
The roads I take...
KaiRo's weBlog
| Zeige die letzten Beiträge auf Englisch und mit "JavaScript" gekennzeichnet an. Zurück zu allen aktuellen Beiträgen | ||||||||||||||||||||||||||||||||||||||||||||||||||
6. April 2020
Sending Encrypted Messages from JavaScript to Python via Blockchain
Of course, we cannot send a physical item to an Ethereum address (which is just a mostly-random number) so we needed a way for the owner of the NFT to give us (or actually Post AG) a postal address to send the physical stamp to. For this, we added a form to allow them to enter the postal address for stamps that were bought via the OnChain shop - but then the issue arose of how would we would verify that the sender was the actual owner of the NFT. Additionally, we had to figure out how do we do this without requiring a separate database or authentication in the back end, as we also did not need those features for anything else, since authentication for purchases are already done via signed transactions on the blockchain, and any data that needs to be stored is either static or on the blockchain.
We can easily verify the ownership if we send the information to a Smart Contract function on the blockchain, given that the owner has proven to be able to do such calls by purchasing via the OnChain shop already, and anyone sending transactions there has to sign those. To not need to store the whole postage address in the blockchain state database, which is expensive, we just emit an event and therefore put it in the event log, which is much cheaper and can still be read by our back end service and forwarded to Post AG. But then, anything sent to the public Ethereum blockchain (no matter if we put it into state or logs afterwards) is also visible to everyone else, and postal address are private data, so we need to ensure others reading the message cannot actually read that data.
So, our basic idea sounded simple: We generate a public/private key pair, use the public key to encrypt the postage address on the website, call a Smart Contract function with that data, signed by the user, emit an event with the data, and decrypt the information on the back-end service when receiving the event, before forwarding it to the actual shipping department in a nice format. As someone who has heard a lot about encryption but not actually coded encryption usage, I was surprised how many issues we ran into when actually writing the code.
So, first thing I did was seeing what techniques there are for sending encrypted messages, and pretty soon I found ECIES and was enthusiastic that sending encrypted messages was standardized, there are libraries for this in many languages and we just need to use implementations of that standard on both sides and it's all solved! Yay!
So I looked for ECIES libraries, both for JavaScript to be used in the browser and for Python, making sure they are still maintained. After some looking, I settled for eccrypto (JS) and eciespy, which both sounded pretty decent in usage and being kept up to date. I created a private/public key pair, trying to encrypt back and forth via eccrypto worked, so I went for trying to decrypt via eciespy, with great hope - only to see that
eccrypto.encrypt() results in an object with 4 member strings while eciespy expects a string as input. Hmm.With some digging, I found out that ECIES is not the same as ECIES. Sigh. It's a standard in terms of providing a standard framework for encrypting messages but there are multiple variants for the steps in the standardized mechanism, and both sides (encryption and decryption) need to agree on using the same to make it work correctly. Now, both eccrypto and eciespy implement exactly one variant, and of course two different ones, of course. Things would have been too easy if the implementations would be compatible, right?
So, I had to unpack what ECIES does to understand better what happens there. For one thing, ECIES basically does an ECDH exchange with the receiver's public key and a random "ephemeral" private key to derive a shared secret, which is then used as the key for AES-encrypting the message. The message is sent over to the recipient along with the AES parameters (IV, MAC) and the "ephemeral" public key. The recipient can use that public key along with their private key in ECDH, get the same shared secret, and do another round of AES with the given parameters to decrypt (as AES is symmetric, i.e. encryption and decryption are the same operation).
While both libraries use the secp256k1 curve (which incidentally is also used by Ethereum and Bitcoin) for ECDH, and both use AES-256, the main difference there, as I figured, is the AES cipher block mode - eccrypto uses CBC while eciespy uses GCM. Both modes are fine for what we are doing here, but we need to make sure we use the same on both sides. And additional difference is that eccrypto gives us the IV, MAC, ciphertext, and ephemeral public key as separate values while eciespy expects them packed into a single string - but that would be easier to cope with.
In any case, I would need to change one of the two sides and not use the simple-to-use libraries. Given that I was writing the Python code while my collegues working on the website were already busy enough with other feature work needed there, I decided that the JavaScript-side code would stay with eccrypto and I'd figure out the decoding part on the Python side, taking apart and adapting the steps that ecies would have done.
We'd convert the 4 values returned from
eccrypto.encrypt() to hex strings, stick them into a JSON and stringify that to hand it over to the blockchain function - using code very similar to this:
var data = JSON.stringify(addressfields);
var eccrypto = require("eccrypto");
eccrypto.encrypt(pubkey, Buffer(data))
.then((encrypted) => {
var sendData = {
iv: encrypted.iv.toString("hex"),
ephemPublicKey: encrypted.ephemPublicKey.toString("hex"),
ciphertext: encrypted.ciphertext.toString("hex"),
mac: encrypted.mac.toString("hex"),
};
var finalString = JSON.stringify(sendData);
// Call the token shipping function with that final string.
OnChainShopContract.methods.shipToMe(finalString, tokenId)
.send({from: web3.eth.defaultAccount}).then(...)...
};
So, on the Python side, I went and took the ECDH bits from eciespy, and by looking at eccrypto code as an example and the relevant Python libraries, implemented code to make AES-CBC work with the data we get from our blockchain event listener. And then I found out that it still did not work, as I got garbage out instead of the expected result. Ouch. Adding more debug messages, I realized that the key used for AES was already wrong, so ECDH resulted in the wrong shared secret. Now I was really confused: Same elliptic curve, right public and private keys used, but the much-proven ECDH algorithm gives me a wrong result? How can that be? I was fully of disbelief and despair, wondering if this could be solved at all.
But I went for web searches trying to find out why in the world ECDH could give different results on different libraries that all use the secp256k1 curve. And I found documents of that same issue. And it comes down to this: While standard ECDH returns the x coordinate of the resulting point, the libsecp256k1 developers (I believe that's a part of the Bitcoin community) found it would be more secure to instead return the SHA256 hash of both coordinates of that point. This may be a good idea when everyone uses the same library, but eccrypto uses a standard library while eciespy uses libsecp256k1 - and so they disagree on the shared secret, which is pretty unhelpful in our case.
In the end, I also replaced the ECDH pieces from eciespy with equivalent code using a standard library - and suddenly things worked! \o/
I was fully of joy, and we had code we could use for Crypto stamp - and since the release in June 2019, this mechanism has been used successfully for over a hundred shipments of stamps to postal addresses (note that we had a limited amount available in the OnChainShop).
So, here's the Python code used for decrypting (we
pip install eciespy cryptography in our virtualenv - not sure if eciespy is still needed but it may for dependencies we end up using):
from Crypto.Cipher import AES
import hashlib
import hmac
from cryptography.hazmat.primitives.asymmetric import ec
from cryptography.hazmat.backends import default_backend
def ecies_decrypt(privkey, message_parts):
# Do ECDH via the cryptography module to get the non-libsecp256k1 version.
sender_public_key_obj = ec.EllipticCurvePublicNumbers.from_encoded_point(ec.SECP256K1(), message_parts["ephemPublicKey"]).public_key(default_backend())
private_key_obj = ec.derive_private_key(Web3.toInt(hexstr=privkey),ec.SECP256K1(), default_backend())
aes_shared_key = private_key_obj.exchange(ec.ECDH(), sender_public_key_obj)
# Now let's do AES-CBC with this, including the hmac matching (modeled after eccrypto code).
aes_keyhash = hashlib.sha512(aes_shared_key).digest()
hmac_key = aes_keyhash[32:]
test_hmac = hmac.new(hmac_key, message_parts["iv"] + message_parts["ephemPublicKey"] + message_parts["ciphertext"], hashlib.sha256).digest()
if test_hmac != message_parts["mac"]:
logger.error("Mac doesn't match: %s vs. %s", test_hmac, message_parts["mac"])
return False
aes_key = aes_keyhash[:32]
# Actual decrypt is modeled after ecies.utils.aes_decrypt() - but with CBC mode to match eccrypto.
aes_cipher = AES.new(aes_key, AES.MODE_CBC, iv=message_parts["iv"])
try:
decrypted_bytes = aes_cipher.decrypt(message_parts["ciphertext"])
# Padding characters (unprintable) may be at the end to fit AES block size, so strip them.
unprintable_chars = bytes(''.join(map(chr, range(0,32))).join(map(chr, range(127,160))), 'utf-8')
decrypted_string = decrypted_bytes.rstrip(unprintable_chars).decode("utf-8")
return decrypted_string
except:
logger.error("Could not decode ciphertext: %s", sys.exc_info()[0])
return False
So, this mechanism has caused me quite a bit of work and you probably don't want to know the word I shouted at my computer at times while trying to figure this all out, but the results works great, and if you are ever in need of something like this, I hope I could shed some light on how to achieve it!
For further illustration, here's a flow graph of how the data gets from the user to Post AG in the end - the ECIES code samples are highlighted with light blue, all encryption-related things are blue in general, red is unencrypted data, while green is encrypted data:
Thanks to Post AG and Capacity for letting me work on interesting projects like that - and keep checking crypto.post.at for news about the next iteration of Crypto stamp!
Von KaiRo, um 17:04 | Tags: blockchain, capacity, Crypto stamp, ECIES, encrytion, Ethereum, JavaScript, Python | 1 Kommentar | TrackBack: 1
8. Mai 2013
Editing Maps in JavaScript
The OpenStreetMap project has launched an all-in-JavaScript map editor called "iD" this week:
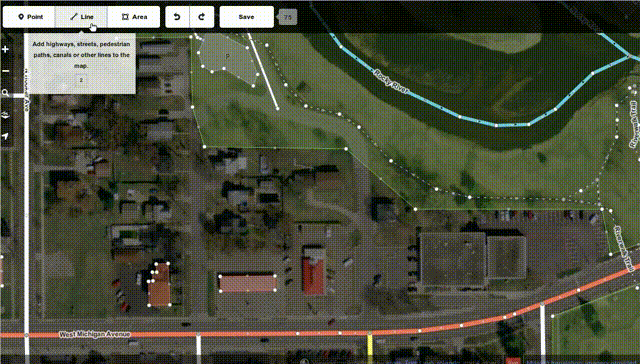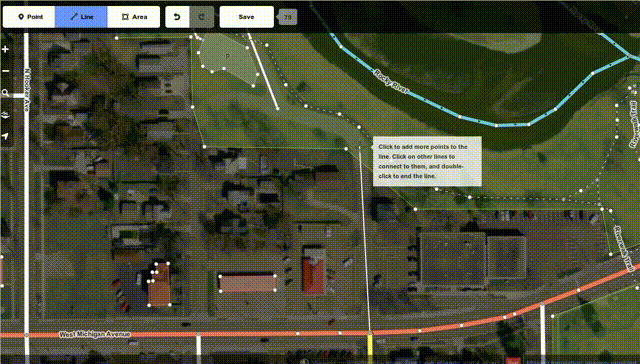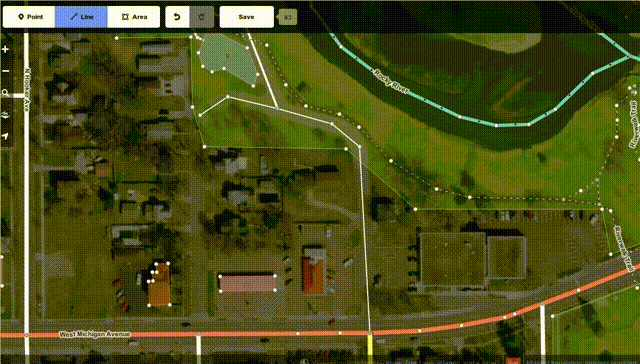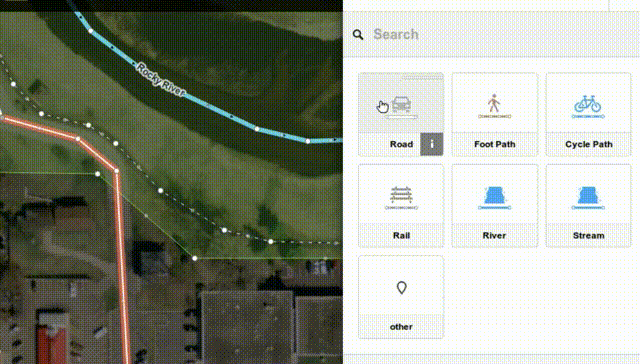
While we at Mozilla know you can do a lot of good things in JS these days - after all, we're even launching our own phone OS building fully on HTML+JS, and we have been using more and more JS code to power key functionality in our browsers and other products over the years - it's great to see that complex things like editing maps can be done fully in JS and available for all platforms now, while previously it took proprietary and availability-limited technologies like Flash or Java to do the same thing.
Great work, OpenStreetMap guys!
(And yes, as a contributor to OpenStreetMap and even OSMF member, I am biased, but free and open map data on the web fits Mozilla philosophy pretty well anyhow...)
While we at Mozilla know you can do a lot of good things in JS these days - after all, we're even launching our own phone OS building fully on HTML+JS, and we have been using more and more JS code to power key functionality in our browsers and other products over the years - it's great to see that complex things like editing maps can be done fully in JS and available for all platforms now, while previously it took proprietary and availability-limited technologies like Flash or Java to do the same thing.
Great work, OpenStreetMap guys!
(And yes, as a contributor to OpenStreetMap and even OSMF member, I am biased, but free and open map data on the web fits Mozilla philosophy pretty well anyhow...)
Von KaiRo, um 16:12 | Tags: JavaScript, Mozilla, OSM | 3 Kommentare | TrackBack: 0
22. September 2010
The Speed of JavaScript in SeaMonkey
In the last days, I did some JavaScript performance tests on different SeaMonkey versions on my machine, just to find out where we are heading for SeaMonkey 2.1 in comparison to what we shipped in the past:
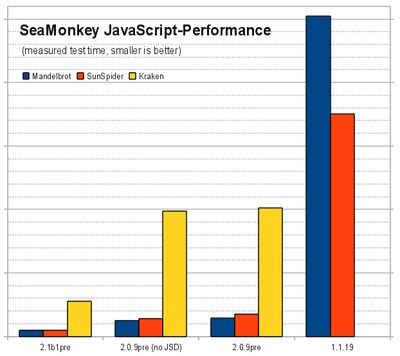
I ran 3 tests there: my personal Mandelbrot demo 1.0 with default settings (blue), the pretty common SunSpider benchmark (red), and the new Kraken benchmark (yellow). Note that the scale of Kraken results is different to the scale of the other two.
(Update/Note: I was told that my Mandelbrot demo uses JavaScript 1.7 and HTML5 features that Mozilla 1.8 supported but other browsers still don't, so there's a more cross-browser Mandelbrot demo 2.0 now - that one performs even a tad better on Mozilla trunk than the results here.)
The builds I tested were current pre-2.1 trunk builds, which already have the first stage of the new JaegerMonkey JavaScript engine, 2.0 branch builds without and with the venkman JavaScript Debugger add-on enabled (without JSD means that TraceMonkey can fully work, as activating venkman makes JSD put JavaScript into a non-tracing debug mode) - and finally, the 1.1.19 release build.
Unfortunately, I can't get data for Kraken on 1.1.19, as after a very very long time of running (given the "slow JavaScript" warning is deactivated), it errors out with not finding any JSON support. Comparing to the other tests, it suffices to say that SeaMonkey 1.1.x, coming from the Mozilla 1.8 tree, is very slow - but then, that's the baseline we started from.
SeaMonkey 2.0.x - even with venkman on and JSD knocking tracing off - is 90% or more faster than 1.1.x in those tests we can run in the older version. Suffice to say that Mozilla's JS team has made tremendous improvements between the 1.8 and 1.9.1 branches of the platform. One might think it's hard to go even further after such a jump, and indeed it has become much harder - but things could still get better. First, turning the debugger off and tracing on wins 19% in SunSpider, 13% for Mandelbrot and 2% for Kraken (the latter either doesn't have a lot of tight loops, which is what tracing help most with, or we are bad at tracing them in this version). At this level, SeaMonkey 2.0 looks already nice - but that's still 1-2 years old code, and development continued.
The current pre-2.1 builds of SeaMonkey bring another 61% win on Mandelbrot, 66% on SunSpider and 72% on Kraken - over 2.0 with full tracing! While the basic Mandelbrot set image took over 25 seconds to calculate and display on 1.1 and significantly over a second on 2.0, we're under half a second now for pre-2.1 code. And, as I already mentioned, JaegerMonkey work isn't even finished yet, there's a few more things to come there.
Of course, the question is if what those tests run is what Web sites and applications really need - we know a few things in SunSpider are non-realistic workloads. Kraken tries to look into CPU-intense workloads that could be useful for actual web applications, esp. if they want to to things like image and audio processing. My Mandelbrot set demo may look far-fetched, but then, I can surely see websites or even more web games dynamically generating fractal-based shades and textures based on variable parameters, and there you might have very similar code.
For those people who want the hard facts, here's the numbers for my graph with all details:Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.1.13pre) Gecko/20100913 Lightning/1.0b2pre SeaMonkey/2.0.9pre Mandelbrot: 1421.8ms +/- 5.0% (1.336, 1.401, 1.497, 1.383, 1.492) SunSpider: 1738.0ms +/- 2.6% Kraken: 40428.1ms +/- 1.6% Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.1.13pre) Gecko/20100913 Lightning/1.0b2pre SeaMonkey/2.0.9pre (venkman disabled) Mandelbrot: 1237.6ms +/- 3.3% (1.220, 1.216, 1.301, 1.197, 1.254) SunSpider: 1402.2ms +/- 3.6% Kraken: 39558.9ms +/- 1.5% Mozilla/5.0 (X11; U; Linux i686; de-AT; rv:1.8.1.24) Gecko/20100301 SeaMonkey/1.1.19 Mandelbrot: 25214.2ms +/- 1.0% (25.176, 24.907, 25.180, 25.216, 25.592) SunSpider: 17501.2ms +/- 1.2% Kraken: Runs slowly for a while, but does break for not finding JSON handling. All in all, the Mozilla JavaScript team is really enabling a lot of new possibilities here, as now we can do things client-side we needed to do server-side up to now, and that makes completely new dynamics possible. And SeaMonkey fully features those improvements made by the Mozilla community.
I ran 3 tests there: my personal Mandelbrot demo 1.0 with default settings (blue), the pretty common SunSpider benchmark (red), and the new Kraken benchmark (yellow). Note that the scale of Kraken results is different to the scale of the other two.
(Update/Note: I was told that my Mandelbrot demo uses JavaScript 1.7 and HTML5 features that Mozilla 1.8 supported but other browsers still don't, so there's a more cross-browser Mandelbrot demo 2.0 now - that one performs even a tad better on Mozilla trunk than the results here.)
The builds I tested were current pre-2.1 trunk builds, which already have the first stage of the new JaegerMonkey JavaScript engine, 2.0 branch builds without and with the venkman JavaScript Debugger add-on enabled (without JSD means that TraceMonkey can fully work, as activating venkman makes JSD put JavaScript into a non-tracing debug mode) - and finally, the 1.1.19 release build.
Unfortunately, I can't get data for Kraken on 1.1.19, as after a very very long time of running (given the "slow JavaScript" warning is deactivated), it errors out with not finding any JSON support. Comparing to the other tests, it suffices to say that SeaMonkey 1.1.x, coming from the Mozilla 1.8 tree, is very slow - but then, that's the baseline we started from.
SeaMonkey 2.0.x - even with venkman on and JSD knocking tracing off - is 90% or more faster than 1.1.x in those tests we can run in the older version. Suffice to say that Mozilla's JS team has made tremendous improvements between the 1.8 and 1.9.1 branches of the platform. One might think it's hard to go even further after such a jump, and indeed it has become much harder - but things could still get better. First, turning the debugger off and tracing on wins 19% in SunSpider, 13% for Mandelbrot and 2% for Kraken (the latter either doesn't have a lot of tight loops, which is what tracing help most with, or we are bad at tracing them in this version). At this level, SeaMonkey 2.0 looks already nice - but that's still 1-2 years old code, and development continued.
The current pre-2.1 builds of SeaMonkey bring another 61% win on Mandelbrot, 66% on SunSpider and 72% on Kraken - over 2.0 with full tracing! While the basic Mandelbrot set image took over 25 seconds to calculate and display on 1.1 and significantly over a second on 2.0, we're under half a second now for pre-2.1 code. And, as I already mentioned, JaegerMonkey work isn't even finished yet, there's a few more things to come there.
Of course, the question is if what those tests run is what Web sites and applications really need - we know a few things in SunSpider are non-realistic workloads. Kraken tries to look into CPU-intense workloads that could be useful for actual web applications, esp. if they want to to things like image and audio processing. My Mandelbrot set demo may look far-fetched, but then, I can surely see websites or even more web games dynamically generating fractal-based shades and textures based on variable parameters, and there you might have very similar code.
For those people who want the hard facts, here's the numbers for my graph with all details:
- Mozilla/5.0 (X11; Linux i686; rv:2.0b7pre) Gecko/20100917 Firefox/4.0b7pre SeaMonkey/2.1b1pre
- Mandelbrot: 483.0ms +/- 1.4% (0.481, 0.492, 0.474, 0.487, 0.481)
- SunSpider: 477.4ms +/- 1.1%
- Kraken: 11151.6ms +/- 0.5%
Von KaiRo, um 18:10 | Tags: JaegerMonkey, JavaScript, Mandelbrot, Mozilla, SeaMonkey, SunSpider | 4 Kommentare | TrackBack: 0
14. März 2009
Impressed With Non-JIT JS Speedups
Prompted by Wladmimir's post on the perf cost of venkman, I filed a bug on getting rid of that cost in SeaMonkey, either by fixing the actual problem or not enabling whatever causes this slowdown - even if (what I don't hope) it would mean not shipping venkman in the worst case.
With JS perf tests being the number one rocks/sucks meter of browsers right now, esp. with advanced user and web developers, who are a very major part of our target audience, we cannot afford to look worse than Firefox in SunSpider and similar benchmarks.
But here's the real surprise moment I had in all that:
To get some useful data of what the penalty is and if there a significant difference to the old SeaMonkey 1.1.x series in that, I did run SunSpider in a current comm-central/mozilla-1.9.1-based SeaMonkey 2.0b1pre build and a mozilla-1.8.1-based SeaMonkey 1.1.16pre build:
SeaMonkey 1.1.16pre: 15719.8ms +/- 1.5%
SeaMonkey 2.0b1pre (venkman disabled, JIT.content disabled!): 2751.6ms +/- 2.1%
Now that's impressive. This is interpreted code, without just-in-time compilation, and it's still very significantly faster than the old 1.8.1 JS engine. Good work, SpiderMonkey developers!
And yes, this are results on the same machine, under the same testing conditions, with mostly empty testing profiles.
With JIT, we're even faster, of course:
SeaMonkey 2.0b1pre (venkman disabled): 1954.8ms +/- 9.4%
Unfortunately, the penalty of just having venkman enabled is real though, resulting in a ~17% slowdown in my tests:
SeaMonkey 2.0b1pre (default config): 2289.8ms +/- 10.7%
We really need to find a solution for that, ideally so that we can give our users a JS debugger available in the suite by default but still give everyone at any time where he doesn't want to actually debug JS code the best possible performance.
I continue to be impressed with the work the SpiderMonkey/TraceMonkey team did, though, the current 1.9.1 JS engine is already so much better than what we had in 1.8.1, and it's not even finished up yet.
With JS perf tests being the number one rocks/sucks meter of browsers right now, esp. with advanced user and web developers, who are a very major part of our target audience, we cannot afford to look worse than Firefox in SunSpider and similar benchmarks.
But here's the real surprise moment I had in all that:
To get some useful data of what the penalty is and if there a significant difference to the old SeaMonkey 1.1.x series in that, I did run SunSpider in a current comm-central/mozilla-1.9.1-based SeaMonkey 2.0b1pre build and a mozilla-1.8.1-based SeaMonkey 1.1.16pre build:
SeaMonkey 1.1.16pre: 15719.8ms +/- 1.5%
SeaMonkey 2.0b1pre (venkman disabled, JIT.content disabled!): 2751.6ms +/- 2.1%
Now that's impressive. This is interpreted code, without just-in-time compilation, and it's still very significantly faster than the old 1.8.1 JS engine. Good work, SpiderMonkey developers!
And yes, this are results on the same machine, under the same testing conditions, with mostly empty testing profiles.
With JIT, we're even faster, of course:
SeaMonkey 2.0b1pre (venkman disabled): 1954.8ms +/- 9.4%
Unfortunately, the penalty of just having venkman enabled is real though, resulting in a ~17% slowdown in my tests:
SeaMonkey 2.0b1pre (default config): 2289.8ms +/- 10.7%
We really need to find a solution for that, ideally so that we can give our users a JS debugger available in the suite by default but still give everyone at any time where he doesn't want to actually debug JS code the best possible performance.
I continue to be impressed with the work the SpiderMonkey/TraceMonkey team did, though, the current 1.9.1 JS engine is already so much better than what we had in 1.8.1, and it's not even finished up yet.
Von KaiRo, um 18:39 | Tags: JavaScript, Mozilla, SeaMonkey | 5 Kommentare | TrackBack: 2
23. August 2008
How Fast Is TraceMonkey In Real World?
Everybody is writing about TraceMonkey today, the just-landed-on-trunk version of the SpiderMonkey JavaScript engine with "tracing" JIT compilation for speeding up code that is run repeatedly.
What I wondered is how fast it is in code that is no benchmark but stuff a real application might use. And as I have my "Mandelbrot" fun project as a XULRunner app (see the last paragraph of recent status update post), which naturally does a lot of looping over the same equation, so I thought it might be a good candidate for optimization.
So I fired up the XULRunner app, doing four testruns of "time mandelbrot" (launching a script that runs my XULRunner build from today's trunk code under primitive unix time measuring) and looked at the amount of user and sys time used. I didn't want professional benchmarks, I wanted just a rough estimate of real world numbers, so it was OK that I needed to manually click the "Draw Image" button and manually click "File > Quit" once the CPU usage came down from fully using one core. I only wanted rough numbers to see if there's a visible difference, so I could live with those deficiencies and rounded the average of two runs roughly.
For the unoptimized, heavily JS-object-based approach I already had last week, I got a number that was about the same as I estimated previously - about 96 +/- 2 seconds. When I turned on the
But even though
Having that code activated, I turned on TraceMonkey once again. And now, it really helped: 7 +/- 0.2 seconds! That's about 30% faster!
For already optimized, pure JS math code (which is probably more real-world than nice-looking object stacking), squeezing even 30% more performance out of this calculation is surely nice!
Still, running my old Visual Basic 5 application under Wine has, apart from more features, two advantages to this XULRunner app: For one, it updates the image frame in the UI during calculation and not only at the end of execution, which is better felt performance as you see what it's doing. For the other, it's still 20% faster, using about 5.6 +/- 0.2 seconds with the same instrumentation - and that though people say VB is so slow. Bummer.
So, good work done, TraceMonkey friends. But there's still more potential to use the CPU more efficiently. Keep on the good work!
What I wondered is how fast it is in code that is no benchmark but stuff a real application might use. And as I have my "Mandelbrot" fun project as a XULRunner app (see the last paragraph of recent status update post), which naturally does a lot of looping over the same equation, so I thought it might be a good candidate for optimization.
So I fired up the XULRunner app, doing four testruns of "time mandelbrot" (launching a script that runs my XULRunner build from today's trunk code under primitive unix time measuring) and looked at the amount of user and sys time used. I didn't want professional benchmarks, I wanted just a rough estimate of real world numbers, so it was OK that I needed to manually click the "Draw Image" button and manually click "File > Quit" once the CPU usage came down from fully using one core. I only wanted rough numbers to see if there's a visible difference, so I could live with those deficiencies and rounded the average of two runs roughly.
For the unoptimized, heavily JS-object-based approach I already had last week, I got a number that was about the same as I estimated previously - about 96 +/- 2 seconds. When I turned on the
javascript.options.jit.chrome pref to run it with TraceMonkey, I saw no difference though, still the same, quite slow run time.But even though
Z = Z.square().add(aC); looks good for the Z = Z² + C equation, it's not that efficient to do two JS object creations for every iteration, so earlier in the week, I replaced that nice code with pure math and simple variables only. That helped performance a lot and saved about 90% of the time, cutting it down to about 9.4 +/- a half seconds.Having that code activated, I turned on TraceMonkey once again. And now, it really helped: 7 +/- 0.2 seconds! That's about 30% faster!
For already optimized, pure JS math code (which is probably more real-world than nice-looking object stacking), squeezing even 30% more performance out of this calculation is surely nice!
Still, running my old Visual Basic 5 application under Wine has, apart from more features, two advantages to this XULRunner app: For one, it updates the image frame in the UI during calculation and not only at the end of execution, which is better felt performance as you see what it's doing. For the other, it's still 20% faster, using about 5.6 +/- 0.2 seconds with the same instrumentation - and that though people say VB is so slow. Bummer.
So, good work done, TraceMonkey friends. But there's still more potential to use the CPU more efficiently. Keep on the good work!
Von KaiRo, um 03:45 | Tags: JavaScript, Mandelbrot, Mozilla | 4 Kommentare | TrackBack: 3
